
Databricks Data Engineer Professional Exam — Week 2: MERGE, SCD, and Why Transformations Are Permanent Decisions
Week 2: ETL Mastery — Transformations, MERGE Semantics, and SCD Modeling

Welcome to week 2 of Databricks Data Engineer Professional exam guide.
Week 1 focused on how Databricks expects you to think about data systems: layering, replayability, failure modes, and governance.
Week 2 is where those mental models are applied under pressure—in transformation logic.
This is the part of the exam where:
experienced Spark engineers often over-optimize
incremental logic looks correct but behaves incorrectly over time
pipelines succeed technically while failing operationally
The Professional exam gives the highest weight to transformations because this is where production systems quietly drift from “working” to “untrustworthy.”
1. Why Transformations Dominate the Professional Exam
Transformations are not about moving data.
They are about encoding assumptions:
what constitutes a valid record
how change is interpreted
whether history matters
how late or corrected data behaves
Once encoded, these assumptions are extremely difficult to undo.
The exam reflects this reality.
Most transformation questions are not asking how to implement logic—they are asking:
“Does this logic still hold when data changes, arrives late, or must be reprocessed?”
If the answer is “it depends,” the exam wants to know whether you identified what it depends on.
2. Transformations Are All About Intent
The exam assumes you already know how to write:
joins
filters
aggregations
window functions
What it evaluates is whether your transformations:
preserve semantic meaning
remain correct under reprocessing
fail in observable ways
scale predictably as data grows
A transformation is correct only if it remains correct tomorrow, not just today.
This is why exam questions often describe:
pipelines that “used to work”
jobs that “gradually slowed down”
aggregates that “occasionally differ”
These are not operational but design issues.
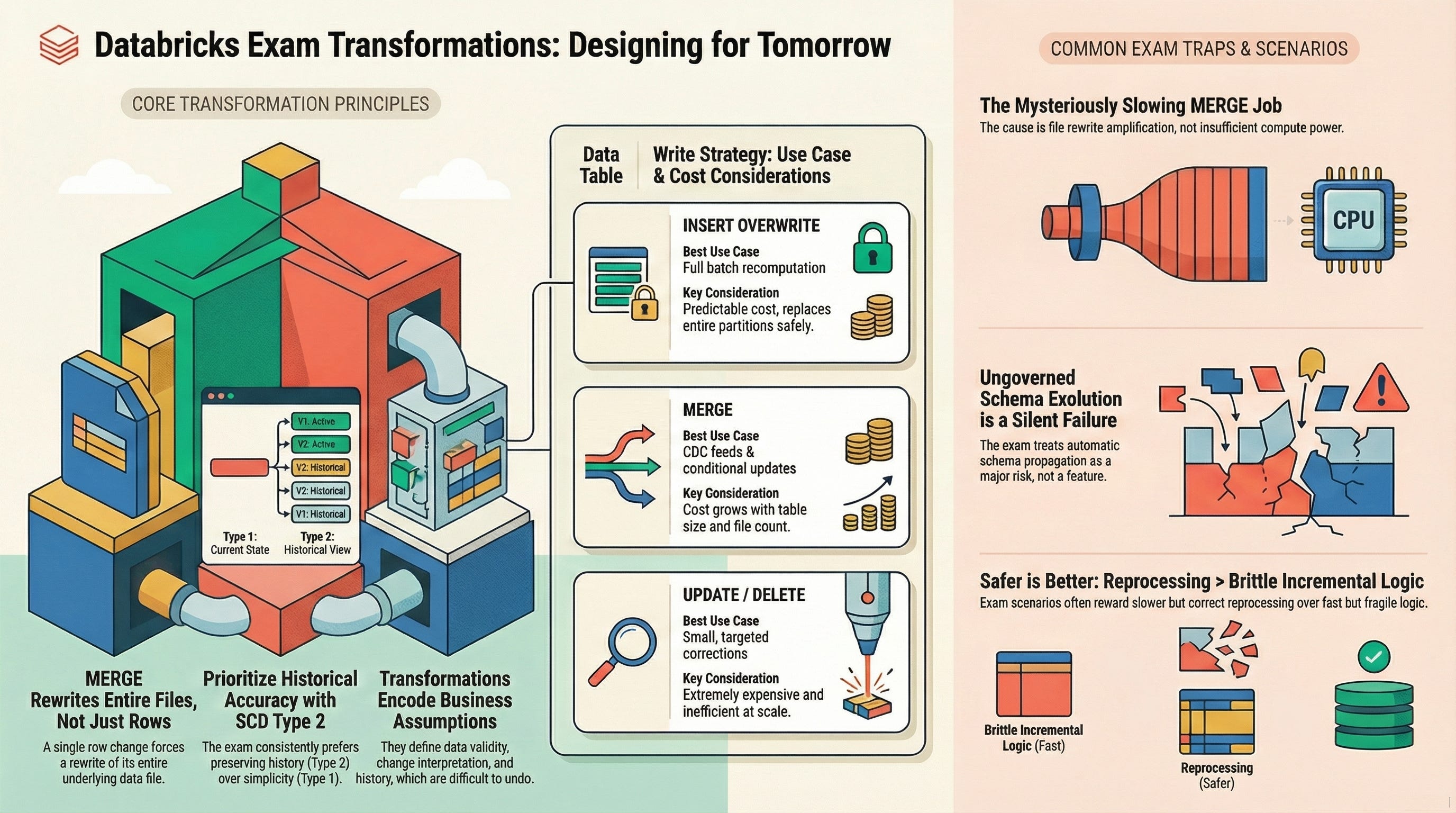
3. Delta Lake MERGE: What Actually Happens
MERGE is the most powerful—and most misunderstood—operation in Delta Lake.
Key fact the exam expects you to internalize
MERGE rewrites files, not rows.
When a MERGE executes:
Delta identifies candidate files in the target table
rows are matched against the join condition
entire Parquet files are rewritten, even if a single row changes
This has several implications the exam tests repeatedly.
What MERGE Is Good At
MERGE is appropriate when:
processing CDC feeds
applying conditional updates
handling SCD logic
updating a small subset of a well-partitioned table
In these cases, MERGE expresses intent clearly and safely.
Where MERGE Becomes Dangerous
MERGE becomes a liability when:
tables are frequently updated
file layout is uncontrolled
a large portion of the table matches the join condition
MERGE is treated as a default write strategy
A classic exam framing:
“This MERGE job keeps getting slower over time, even though data volume is stable.”
The correct answer is rarely “increase cluster size.”
The exam expects you to recognize write amplification caused by file rewrites.
4. Choosing the Right Write Strategy
Delta Lake gives you multiple ways to mutate data.
Each one encodes a different long-term assumption.
UPDATE / DELETE
rewrite entire files
expensive at scale
appropriate only for small, targeted corrections
MERGE
conditional logic
CDC-friendly
cost grows with table size and file count
INSERT OVERWRITE
replaces entire partitions
predictable cost
ideal for batch recomputation
The exam often prefers recompute cleanly over incrementally patch forever.
This is a subtle but important shift from older big-data thinking.
5. Slowly Changing Dimensions (SCD): The Most Tested Pattern
SCDs are a formal way to model how meaning changes over time.
SCD Type 1 — Overwrite History
What it does
updates records in place
removes historical values
Correct when
fixing incorrect data
history does not affect analysis
Dangerous when
historical state matters
reporting depends on point-in-time accuracy
The exam penalizes Type 1 when history is implicitly required—even if not stated explicitly.
SCD Type 2 — Preserve History
What it does
closes existing records
inserts new versions
tracks validity windows
Trade-offs
increased storage
more complex queries
higher MERGE cost
The exam consistently prefers correct historical meaning over simplicity when trade-offs exist.
Critical Exam Insight
SCD choice is not technical—it is semantic.
The correct SCD strategy depends on:
how the data is consumed
whether changes redefine meaning
whether analysts expect historical accuracy
Choosing the wrong SCD type produces data that looks correct—but answers the wrong question.
6. Schema Evolution Inside Transformations
Schema evolution is one of the most common silent failure modes.
Safe evolution
adding optional columns
backward-compatible changes
isolated downstream impact
Dangerous evolution
changing column semantics
tightening nullability
allowing new fields to propagate blindly
The exam tests whether schema evolution is:
intentional
localized
governed
Automatic evolution everywhere is treated as a risk, not a feature.
7. Deduplication and Late-Arriving Data
Deduplication is not DISTINCT.
Correct deduplication requires:
a clear definition of uniqueness
deterministic ordering
explicit handling of late records
Poor deduplication logic leads to:
inconsistent aggregates
non-idempotent pipelines
incorrect reprocessing results
The exam expects window-based reasoning over shortcuts.
8. Incremental Processing vs Reprocessing
Incremental logic assumes:
stable keys
bounded change
correct upstream data
When those assumptions break, incremental pipelines become brittle.
Reprocessing:
costs more
is simpler
is often safer
The exam frequently rewards slower but correct over fast but fragile.
Exam-Style Scenarios
Scenario 1: MERGE Performance Degradation
A Silver table is updated hourly using MERGE.
Data volume is stable, but job duration increases steadily.
Most likely cause?
→ File rewrite amplification due to layout, not compute shortage.
Scenario 2: MERGE vs INSERT OVERWRITE
A daily job recomputes the last 7 days of data.
Better strategy?
→ INSERT OVERWRITE on affected partitions for predictable cost.
Scenario 3: SCD Choice
Customer attributes change and historical reports depend on prior state.
Correct model?
→ SCD Type 2, despite higher cost.
Scenario 4: Schema Evolution Breaks Dashboards
A new column propagates automatically and downstream logic fails.
Design flaw?
→ Schema enforcement happened too late.
Common Pitfalls the Exam Targets
Using MERGE everywhere
Defaulting to SCD Type 1
Ignoring file layout
Treating schema evolution as free
Optimizing before semantics are stable
These are experienced-engineer traps.
Closing Perspective
Transformations are where data engineering stops being mechanical.
They are where judgment becomes permanent.
The Databricks Data Engineer Professional exam is designed to expose pipelines that work today—but fail quietly tomorrow.
Design transformations that survive change, and the exam becomes far more predictable.
Hands-On Companion (GitHub)
This post is accompanied by a small set of Databricks notebooks that surface the behaviors discussed here—MERGE file rewrites, SCD trade-offs, schema evolution risks, and write-strategy decisions.
They are optional, but strongly recommended if you are preparing seriously for the Databricks Data Engineer Professional exam.
→ GitHub repo: Databricks Data Engineer Professional – Study Guide (Week 2)
Up Next
Week 3: Performance & Cost Control
Why “fast” pipelines still bleed DBUs—and how the exam expects you to reason about optimization.